
Modern NLP in Transformers & LLMs
Word embeddings are the unsung heroes of natural language processing. Before transformers took centre stage, embeddings quietly revolutionised how machines interpret language. They turned words into vectors that capture meaning, context, and relationships. Even today, embeddings remain the backbone of LLMs. They power everything from semantic search to zero-shot learning.
Here are seven powerful facts that highlight their impact:
1. Word Embeddings Turn Words into Meaningful Vectors
Unlike one-hot encoding, which treats each word as a separate and unrelated symbol. Word embeddings offer a radically different approach. They map words into dense vector spaces. This is where position, distance, and direction encode rich semantic relationships. This means that similar words—like “happy” and “joyful”—end up closer together, while antonyms or unrelated terms are spaced farther apart.
One of the most striking examples is the famous analogy:king - man + woman ≈ queen
This isn’t a linguistic trick—it’s a mathematical insight. Through training on large corpora, models like Word2Vec and GloVe learn patterns of word usage and context. They then embed these patterns into vector representations. These vectors show word meaning. They also capture subtle patterns, such as gender and verb tense. Some even reflect geographic relationships, like how place names relate to context.
By translating language into structured numerical form. Word embeddings became the stepping stone toward contextual models like BERT and GPT. They’re not just the past of NLP—they’re its hidden architecture.
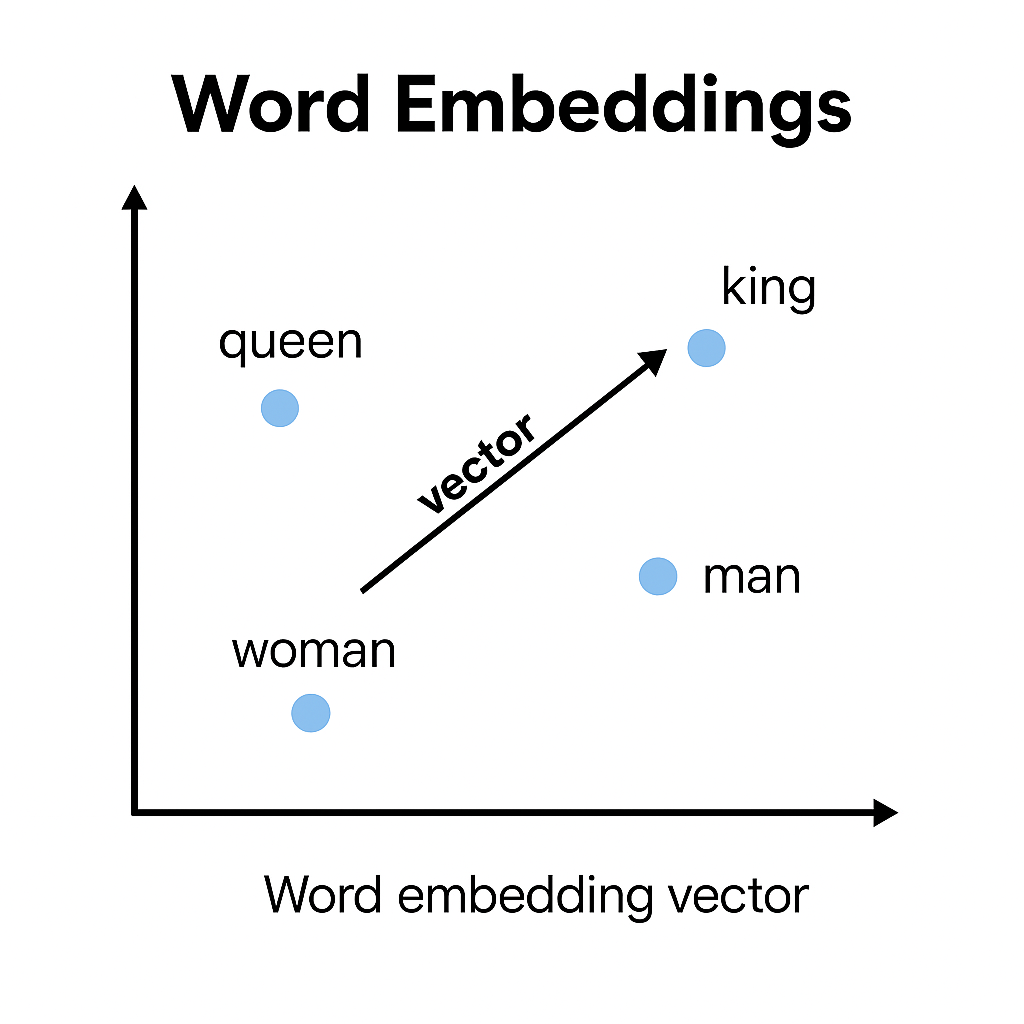
Word embeddings don’t just store words—they position them in a vector space where meaning is measurable. Words with similar meanings cluster together, and analogies like
king - man + woman ≈ queen become directional patterns. This turns language into data that models can understand and reason with.2. Word Embeddings Capture Context—Even Before Transformers Did
Word2Vec includes two models: Skip-gram and CBOW. Both learn word relationships by predicting the words around a target in a sentence. Instead of memorising isolated tokens, they grasp how words relate to each other based on usage and proximity. This process allows models to pick up on context, distinguishing between different meanings of the same word depending on where it appears. For instance, “bank” in “river bank” versus “money bank” gets clarified through neighbouring words.
FastText builds on this idea by embedding sub-word information, such as character n-grams. FastText doesn’t rely only on full words. It also learns patterns from parts of words, like prefixes and suffixes. This makes FastText more flexible. It can deal with typos and spelling mistakes. It also works well with rare or unknown words. For example, if the word “biostatistics” isn’t in the training data, FastText still understands it. It breaks the word into smaller parts like “bio,” “stat,” and “istics.”
These models changed how machines understand language. They helped NLP systems become more accurate and flexible. As a result, modern tools handle complex tasks better and work more reliably in real-world situations.
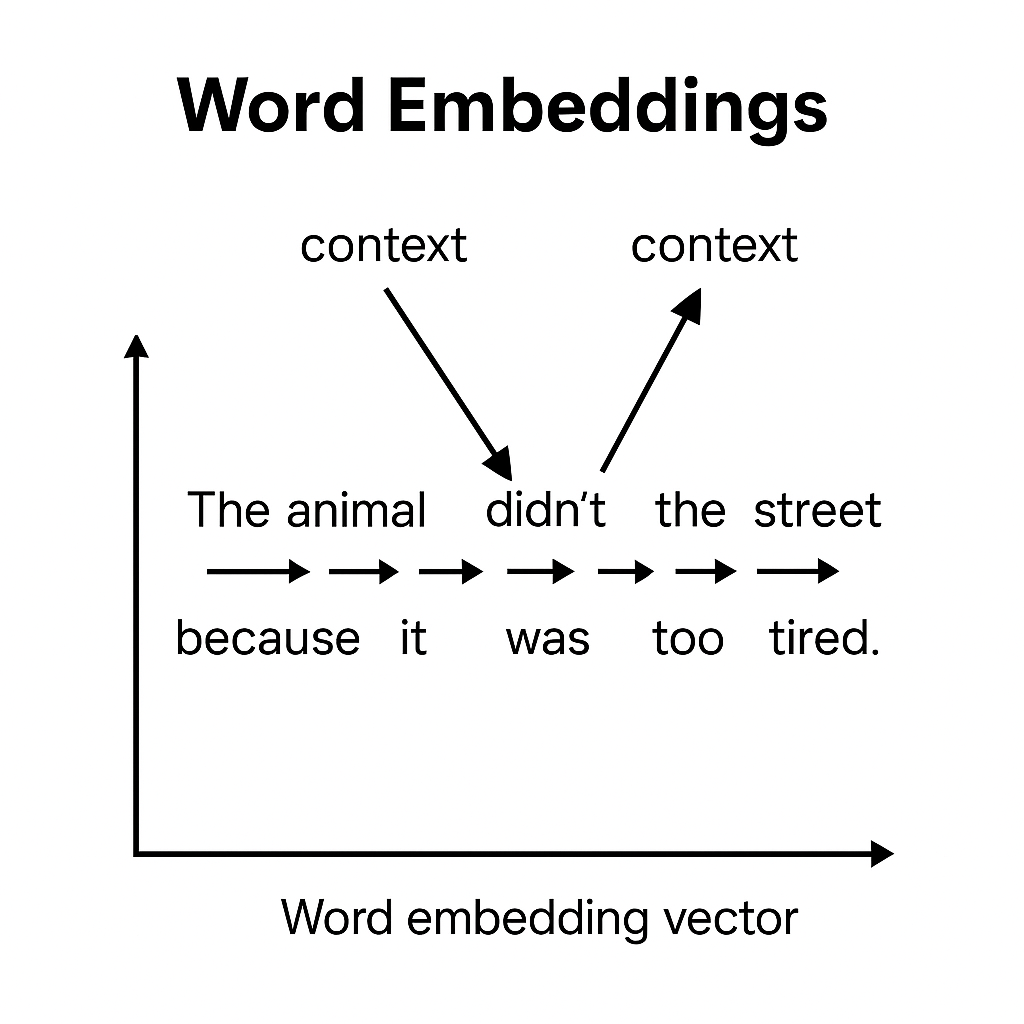
Before transformers, models like Word2Vec used nearby words to learn meaning. Skip-gram and CBOW taught embeddings to capture relationships based on position and usage. This allowed systems to tell the difference between “bank” in “river bank” vs “money bank”—purely through context. It was a major step in teaching machines how language works.
3. Word Embeddings Enable Transfer Learning in NLP
Pre-trained word embeddings are reusable. You can plug them into many NLP tasks. These include sentiment analysis, named entity recognition, and document classification. There’s no need to retrain from scratch. That saves time and computing resources.
This idea helped shape modern NLP. It showed that models could learn general language patterns first. Then, they could adapt to new tasks with less training. This is called transfer learning.
BERT and GPT are examples of large language models that use this approach. They learn from huge amounts of text before fine-tuning. As a result, they work well across many problems—even those they didn’t directly train on.
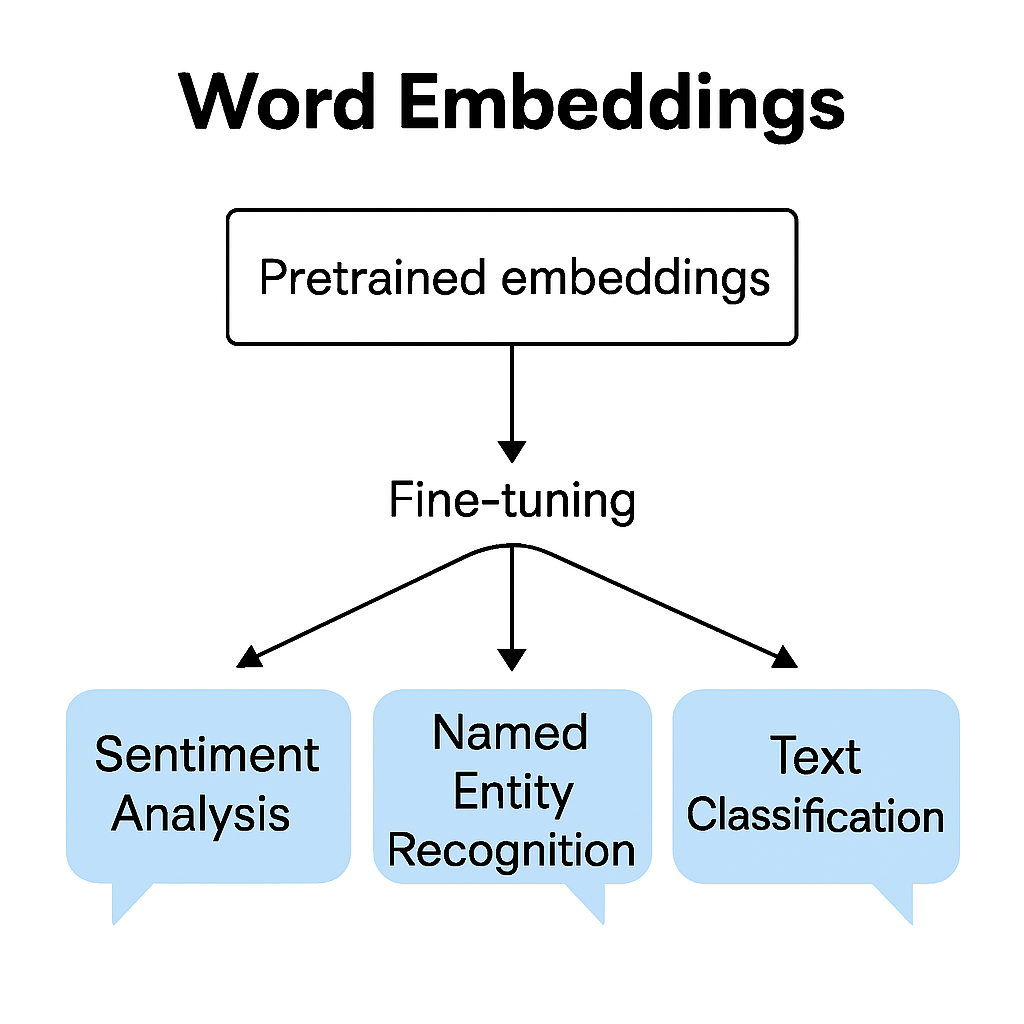
Pre-trained word embeddings learn general patterns from huge datasets. Once trained, they can be reused for many tasks—like sentiment analysis or classification—without starting over. This idea sparked transfer learning in NLP, where models like BERT and GPT learn once, then adapt fast. It’s efficient, flexible, and opens the door to smarter AI.
4. Word Embeddings Are the DNA of Transformer Models
Even advanced models like BERT and GPT start with word embeddings. These embeddings are the first layer of input. They turn words into vectors before any deeper processing begins.
Next, the models apply attention mechanisms. This lets them understand how each word connects to others in the sentence. The attention layers build rich context on top of the initial embeddings.
Transformers don’t ignore embeddings. They enhance them. The result is a deeper, more flexible understanding of language. Embeddings provide the foundation; transformers make it powerful.
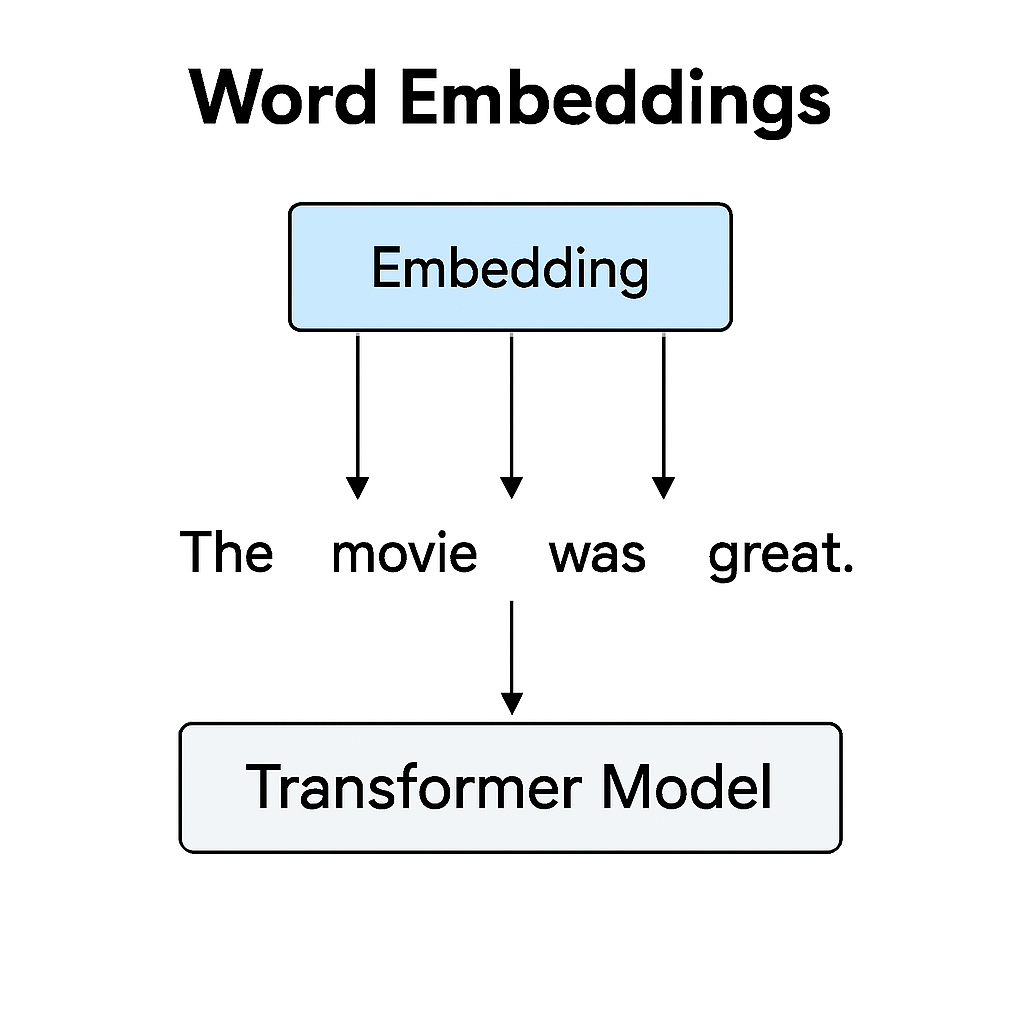
Transformer models don’t start with attention—they start with embeddings. These embeddings translate each token into a meaningful vector before any deeper reasoning happens. Attention layers then build on this foundation to capture context, relationships, and meaning. Without embeddings, transformers wouldn’t have anything to work with—they’re the DNA of modern NLP.
5. Word Embeddings Bridge Language and Vision in Multimodal Models
CLIP and Flamingo are advanced multimodal models. They combine text embeddings with image features. This means they can link words and pictures in a shared space.
Because of this fusion, the models understand both language and visuals. They can classify images without being trained on specific labels. This is called zero-shot image classification.
They also generate captions and answer questions about images. These tasks were once separate. Now, with shared embedding spaces, models can do both using the same understanding.
The key is alignment. Text and image data are mapped into one space. This lets the model compare and reason across different types of input.
Multimodal models like CLIP use shared embedding spaces to link language and vision. Text and image inputs are translated into vectors and mapped side by side. This allows AI to classify images, write captions, or answer questions—without being trained on each task separately. Word embeddings make it all possible by giving meaning a place to meet across formats.
6. Word Embeddings Can Be Fine-Tuned for Specific Domains
General embeddings, like GloVe, learn from large, diverse text datasets. They understand language broadly, covering many topics and writing styles. These embeddings work well for general-purpose NLP tasks.
But specialised problems often need focused knowledge. That’s where domain-specific embeddings come in. These are trained on targeted text—such as medical records, legal documents, or scientific papers. They understand the unique vocabulary and patterns of those fields.
As a result, they perform better on tasks like classifying clinical notes or analysing legal contracts. They’re tuned to the language that matters in those domains.
SpaCy and Hugging Face, among other tools, simplify this process. You can train new embeddings from scratch or adapt existing ones to your own data. This helps you build models that are both accurate and relevant.
General embeddings understand everyday language—but specialised work needs sharper tools. When trained on domain-specific texts, embeddings learn field-specific terms, patterns, and concepts. Tools like spaCy and Hugging Face make this process easier, helping models perform better in areas like healthcare, law, and science. Fine-tuning brings precision to understanding.
7. They Reveal Hidden Biases in Language Models
Word embeddings learn from patterns in human language. As a result, they can pick up social and cultural associations. Some of these patterns reflect stereotypes or biased assumptions.
This means embeddings may unintentionally carry societal bias. For example, they might link certain professions more strongly with one gender. Or they might reflect cultural narratives found in the training data.
Researchers work to identify and reduce these biases. They use methods like hard de-biasing and counterfactual data augmentation. These techniques help adjust embeddings so they’re more fair and balanced.
By auditing and refining embeddings, we can build NLP systems that are more ethical and inclusive.
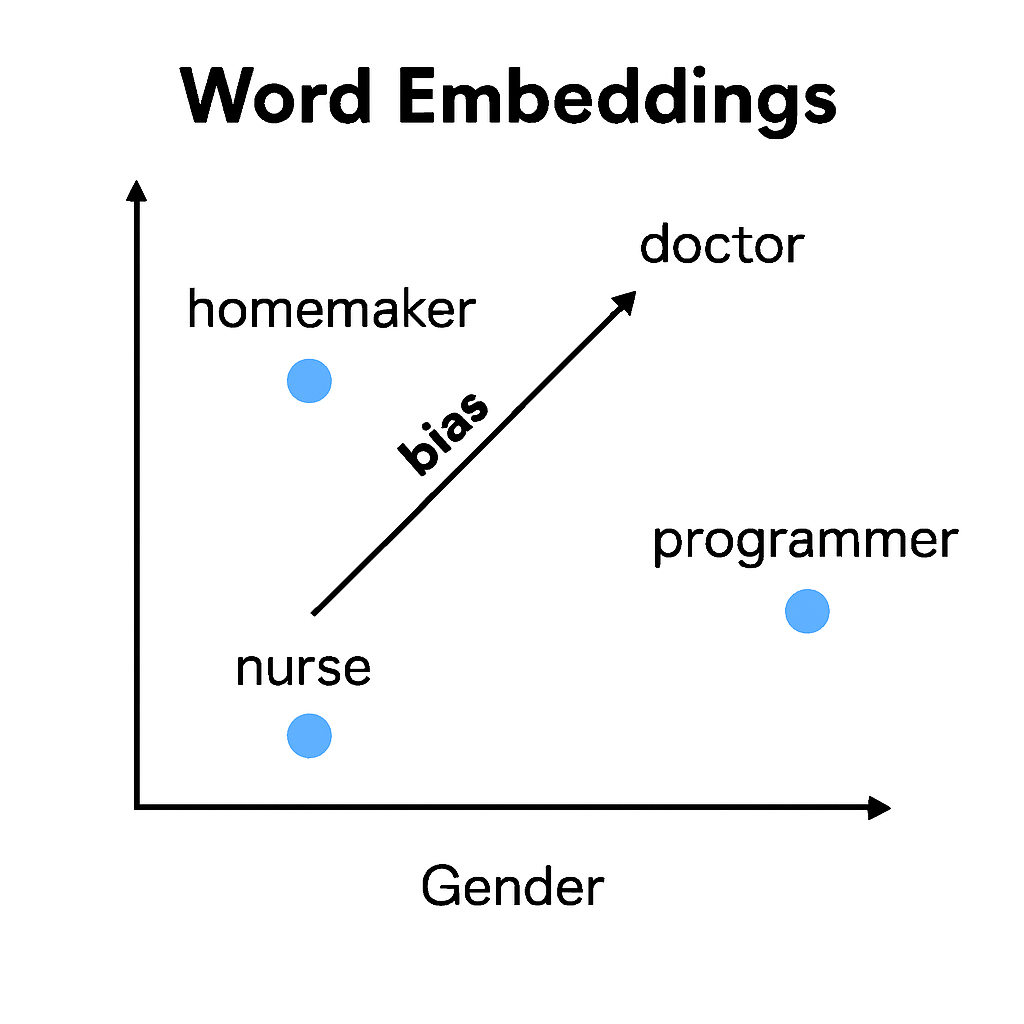
Word embeddings learn from human text—and that means they can absorb human bias. They may associate professions with gender or reflect cultural stereotypes. By analysing these vector patterns, researchers can detect and reduce such bias. Techniques like hard de-biasing and counterfactual augmentation help make AI fairer and responsible. Embeddings show us where language can mislead—and how to fix it.
Final Thoughts
Word embeddings are often hidden behind the scenes. But they shape the way machines understand language. We see them in transformers, in multimodal models, and in systems built to improve fairness.
Embeddings help models learn meaning, context, and relationships between words. They turn messy human language into structured data. That data powers everything from chatbots to search engines.
They are part of almost every modern NLP tool. And they play a vital role in artificial intelligence as a whole.
To build better systems, we need to understand how embeddings work. They are key to the evolution of language technologies. With them, we can create AI that is accurate, adaptable, and more responsible.
If you found this post insightful and want to explore how word embeddings apply to your own NLP or AI projects, let’s connect. I enjoy sharing ideas and learning from others in the field. Reach out here and let’s keep the conversation going.
Explore Further
If you’re curious to dive deeper into the foundations and applications of word embeddings. These resources offer a great starting point:
- Word2Vec: Word Embedding using Word2Vec
- GloVe: Global Vectors for Word Representation
- FastText: Library for Efficient Text Classification and Representation Learning
- spaCy: Training Custom Word Embeddings
- Hugging Face: Token Embeddings and Fine-tuning
- CLIP: Learning Transferable Visual Models From Natural Language Supervision